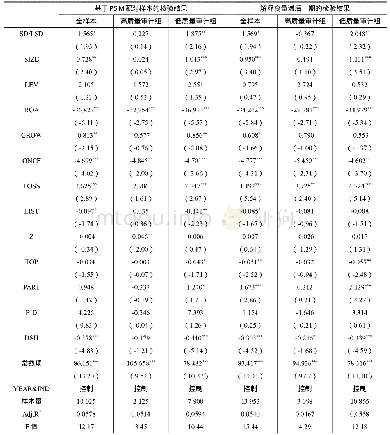
《表6 倾向得分匹配法 (PSM) 、解释变量滞后一期的内生性检验》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:括号内数值为t值,***、**、*分别表示在1%、5%、10%的水平上显著(双尾);本表中的回归结果在公司层面进行了聚类调整 (cluster)
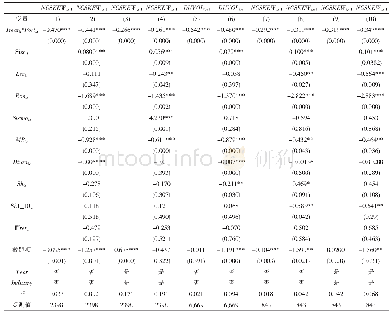
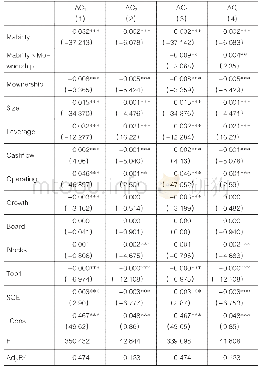
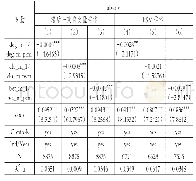
第一,倾向得分匹配法(PSM)。本文设定的模型可能存在遗漏变量问题,为控制因遗漏变量产生的内生性影响,我们采用倾向得分匹配法(PSM)构建配对样本进一步检验。根据战略差异度(SD)是否大于其行业年度均值的标准划分处理组和控制组,并采用Logistic回归模型计算倾向得分,以公司规模(SIZE)、资产负债率(LEV)、资产收益率(ROA)、成长能力(GROW)、经营现金净流量(ONCF)、上市年数(LIST)、股权制衡度(Z)、第一大股东持股(TOP)、独立董事比例(PID)、董事会会议次数(DSH)、年度变量(YEAR)和行业变量(IND)作为匹配变量,按最邻近匹配原则进行1:1配对,结果发现,匹配变量的标准偏差绝对值(Bias)最大为3.3%,年报披露及时性(ALAG)的平均处理效应(ATT)所对应的T值为2.65,在1%的水平上显著,说明相较于战略差异度较小的公司,战略差异度较大的公司年报披露时滞更长,年报披露及时性更差。如表6所示,PSM配对样本的检验结果显示,战略差异度(SD)与年报披露及时性(ALAG)在10%的水平上显著正相关,且这种正相关关系只在低质量审计组中显著存在,与前文研究结论一致。
| 图表编号 | XD0013164900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.09.25 |
| 作者 | 刘圻、罗忠莲 |
| 绘制单位 | 中南财经政法大学会计学院、中南财经政法大学会计学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}