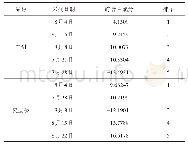
《表2 随机采摘实验下设置不同奖励函数的采摘性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了验证本文方法相较于其他方法的有效性,进行不同奖励函数下的采摘性能对比实验,不同奖励函数分为4种:(1)无障碍惩罚奖励函数,即虚拟机器人在训练过程中与障碍物发生碰撞只单纯进行次数记录,不会进行惩罚,用于判断随机采摘点与随机障碍物对虚拟机器人采摘产生影响的概率。(2)普通奖励函数,即虚拟机器人在训练过程中与障碍物发生碰撞进行惩罚,而在接近障碍过程中无惩罚。(3)基于人工势场法的奖励函数,即虚拟机器人在训练过程中,当其靠近障碍物时,给予惩罚,惩罚值与虚拟机器人和障碍物的距离成反比。(4)改进人工势场法方向惩罚奖励函数,即本文方法。所有奖励函数的目标导引机制相同。随机采摘实验下设置不同奖励函数的采摘性能如表2所示。采摘成功数即虚拟机器人成功避开障碍物到达目标采摘点的次数,使用时间指成功完成200次采摘任务所需时间。由无障碍惩罚奖励函数采摘成功数可知,随机障碍对采摘任务的影响率大约28%,相较于普通奖励函数,基于人工势场法的奖励函数和本文方法的避障效果显著,其采摘成功率分别达到93.5%和97.5%,分别比普通奖励函数方法提高了7个百分点和11个百分点;但使用时间上,基于人工势场法奖励函数由于会产生不必要的惩罚,导致虚拟机器人为了躲避障碍物而选择一条路程较远的路径,采摘时间较长,本文方法能够有效减少这种情况产生的影响,只使用了124 s,平均耗时0.64 s/次,相较于基于人工势场法奖励函数方法降低了0.45 s/次,说明其规划路程相对最短,有利于提高采摘效率,减少资源消耗。
| 图表编号 | XD00192788300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.18 |
| 作者 | 熊俊涛、李中行、陈淑绵、郑镇辉 |
| 绘制单位 | 华南农业大学数学与信息学院、华南农业大学数学与信息学院、华南农业大学数学与信息学院、华南农业大学数学与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}