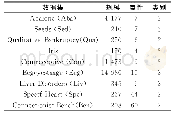
《表1 多种数据集对比:引入全局算法的小批量K-Means》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验采用从UCI上下载的数据集和模拟数据集.流程图见图2,数据集对比见表1.Iris数据集的每个实例有4种属性,包括花瓣和萼片的长宽度.一共有3个类别,每个类别包含50个实例,每个类别代表一种虹膜植物.通过实验能快速的将属于同一类别的数据聚类.Travel Reviews数据集的每个实例有11个属性,分别对东亚地区提及的10个类别的目的地进行了评估.每个旅行者评级被映射为优秀(4),非常好(3),平均(2),差(1)和可怕(0),并且对每个用户的每个类别使用平均评级.通过实验可以将评级相同的聚类在一起.随机数据一个有10 000个实例,每个实例有横纵坐标2个属性,通过实验将这10 000个实例分为3类,每个类中的实例更加紧密,类别之间的实例相距很远.
| 图表编号 | XD00166443600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.25 |
| 作者 | 王颖、吴观茂 |
| 绘制单位 | 安徽理工大学计算机科学与工程系、安徽理工大学计算机科学与工程系 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}