《表2 所用数据集:基于Spark的改进K-means算法的并行实现》
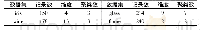 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Spark的改进K-means算法的并行实现》
本文在Spark分布式集群上实现了改进K-means算法,它由一台master主节点和三台slave从节点组成,每台机器的硬件配置都是:CPU双核2.5 GHz,内存4 GB,硬盘500 GB。操作系统是64位Ubuntu 16.04。测试采用的数据集是从UCI标准数据库下载的iris、wine、glass、flame四个数据集,如表2所示。
| 图表编号 | XD00134614700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 杜佳颖、段隆振、段文影、卜秋瑾 |
| 绘制单位 | 南昌大学信息工程学院、南昌大学信息工程学院、南昌大学信息工程学院、南昌大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}