《表2 实验数据集描述:一种融合三支决策理论的改进K-means算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
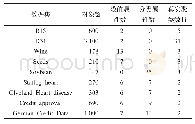
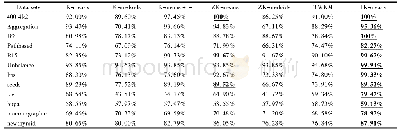
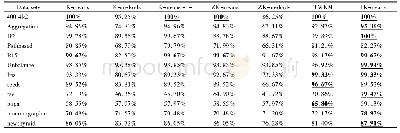
本文的实验采用Java语言编写,具体的实验环境如表1所示.为了验证本文提出的TK-means算法的性能,仿真实验共选择了12个数据集,其中6个模拟数据集:400-4k2、Aggregation、D9、Pathbased、R15和Unbalance,6个UCI机器学习库中的真实数据集:Iris、seeds、tae、bupa、mammographic和newthyroid.表2展示这些数据集的详细信息,其中参数Effect为区分核心区域和边缘区域的参数.真实数据集均为高维度的数据集,需要通过降维处理才能在低维度空间中展示.本文采用T-SNE方法对高纬度数据集进行降维处理[17].图1和图2分别是模拟数据集和降维后的真实数据集的空间分布图.
| 图表编号 | XD00141260600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 夏月月、张以文 |
| 绘制单位 | 安徽大学计算机科学与技术学院、安徽大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}