《表1 文本测试集分类:基于Spark的大规模文本KNN并行分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
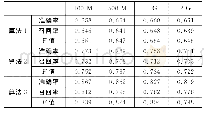
在Spark计算框架中对得到的新训练文本集进行下一步的KNN文本分类处理(如表1所示),并在分类过程中迭代K值并获取最终分类结果.最后通过比较准确率、运行时间、加速比来验证算法的执行性能.加速比公式为
| 图表编号 | XD00141021200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.20 |
| 作者 | 李宏志、李苋兰、赵生慧 |
| 绘制单位 | 滁州学院信息学院、福建师范大学光电与信息工程学院、福建师范大学光电与信息工程学院、滁州学院信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}