《表2 实验数据:面向大规模裁判文书结构化的文本分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
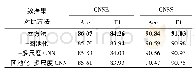
本文提出了基于篇章中的段落级别上下文的裁判文书结构化方法,首先利用经过预训练和下游分类任务微调的BERT模型提取篇章中每一个段落的起始符号[CLS]对应的向量作为段落的特征表示p,然后将整个篇章的若干个段落特征表示输入到序列标注模型中进行标签预测.在实验中,通过消融实验来比较不同的模型提取段落特征的能力以及是否利用段落上下文的结构化信息对结果的影响,将Text CNN模型作为基线模型,与BERT分类模型、Text CNN+Bi-LSTM-CRF模型与BERT+Bi-LSTM-CRF模型分别做实验对比,实验结果如表2所示.
| 图表编号 | XD00209364400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.04.15 |
| 作者 | 翁洋、谷松原、李静、王枫、李俊良、李鑫 |
| 绘制单位 | 四川大学数学学院、四川大学法学院、四川大学数学学院、数之联科技有限公司、数之联科技有限公司、四川大学法学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}