《表2 仿真实验数据选取:面向MapReduce的大数据分类模型及算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
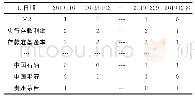
提出实验,验证本文设计的面向Map Reduce的大数据分类模型及算法具备一定研究机制,引入CPU(KDD)公共数据处理技术,搭建大数据挖掘检测数据集合。实验需准备3台计算机设备,一台计算机设备为实验主机,设定主机为数据通过主节点(Master),剩余两台计算机设备匹配子节点数据。设备具体属性值如下:处理器选择因特尔(R)核心(TM),i7-5600运行处理模式;计算机硬盘内存为64GB;外设硬盘运行内存为256 GB;计算机运行系统版本为Ubuntu15.6;JAVA计算机语言包工具运行版本为2.6;集散式系统基础运行框架版本为2.6.4;仿真实验运行环境为集成式开发运行环境,配备Map Reduce数据插件,计算机数据集处理语言选择java。遵循标准测试数据库中数据集,设定该数据集合中共有60万个数据样本,样本中包含55个不同数据属性变量值,依照数据类别划分为8种,占用计算及运行内存79.5 MB。此次实验从60万个数据样本中,随机选取部分数据集合作为此次实验的对照组实验数据,同时选取同样数值的数据集合作为实验组测试数据,为提升实验结果的真实性,两组数据中不可包含重复数据。设定10组实验数据,数据选取具体情况如表2所示。
| 图表编号 | XD00220055100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 柯建波 |
| 绘制单位 | 广东工业大学华立学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}