《表1 文本聚类测试结果:基于改进Canopy-K-means算法的并行化研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于改进Canopy-K-means算法的并行化研究》
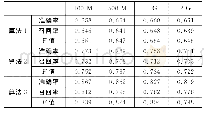
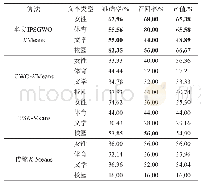
本文以准确率(precision)、召回率(recall)和F值作为评判指标[10]。对比传统K-means算法(算法1),Canopy-K- means算法(算法2)以及本文改进算法(算法3)在文本聚类上的优劣,分别在100 M、500 M、1G和2G数据集各聚类10次,取各项指标的平均值进行比较,结果如表1所示。
| 图表编号 | XD00203521400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.02.25 |
| 作者 | 王林、贾钧琛 |
| 绘制单位 | 西安理工大学自动化与信息工程学院、西安理工大学自动化与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}