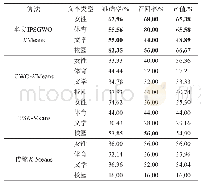
《表1 问卷设计框架:改进灰狼优化算法的K-Means文本聚类》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验结果评估方法:类内距离之和、准确率、召回率和F值。其中,类内距离之和越小代表数据聚合度越高;准确率与召回率都是介于0到1之间,两者结果越靠近1,代表文本聚类算法的查全率越高;F值大小也在0和1之间,其值越大,代表聚类效果越真实可靠。并且将本文所提IPSGWO-KMeans文本聚类算法与传统K-Means算法、IPSK-Means算法以及GWO-KMeans算法[15]进行文本聚类实验对比,其中类内距离之和的收敛情况如图1所示;为了更好地验证所提算法的文本能力,在各个算法稳定状态时,分别取一次较好的准确率、召回率和F值的实验结果进行对比,结果记录如表1所示,加黑字体为实验较优结果。
| 图表编号 | XD00197456900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.01 |
| 作者 | 潘成胜、张斌、吕亚娜、杜秀丽、邱少明 |
| 绘制单位 | 大连大学通信与网络重点实验室、大连大学通信与网络重点实验室、大连大学通信与网络重点实验室、大连大学通信与网络重点实验室、大连大学通信与网络重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}