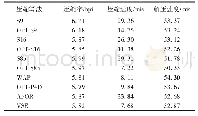
《表1 数据集属性:RDD上扩展索引层优化的分布式K-means算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《RDD上扩展索引层优化的分布式K-means算法》
实验采用了人工生成的数据集和真实数据集进行测试。人工数据集利用了Python的NumPy库生成的混合高斯模型数据集来进行测试。在20维空间下,随机生成中心点集C,再分别围绕这些中心按照随机标准偏差[0,10.0]生成高斯分布的k个簇、所有点的数量和为N。实验测试的数据集大小在103~5.0×106之间,簇的个数在10~20之间。除此之外,实验还采用了真实数据集,选用了来源于http://archive.ics.uci.edu/ml/datasets.html的Anuran Calls(R1)与Individual household electric power consumption(R2)。表1给出了所有数据集的属性。
| 图表编号 | XD0035426000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.01 |
| 作者 | 马菁、李力 |
| 绘制单位 | 上海交通大学计算机科学与工程系、贵州大学贵州省公共大数据重点实验室、上海交通大学软件学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}