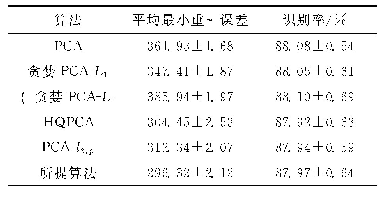
《表1 在MNIST数据集上不同优化算法的结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
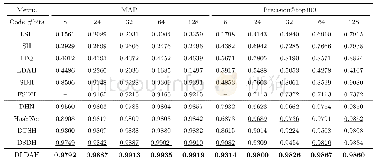
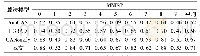
在收敛方面,本文的3组实验都是Adagrad优化算法收敛最快,但是Adagrad优化算法所得到结果的F1值普遍不高,这是因为Adagrad流程中式子的分母随着时间单调递增。当分母积累值过大后,收敛变得很小,导致训练后期变化幅度很小。对于SGD和Momentum,随机的特性导致了其收敛本身就不快,它们所得F1值也不高。对于RMSProp、Adam、RAdam则可以在保证较快收敛的前提下,同时得到较高的F1值。
| 图表编号 | XD00222683300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.10 |
| 作者 | 刘然、刘宇、顾进广 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学)、武汉科技大学大数据科学与工程研究院、国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室(武汉科技大学)、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学)、武汉科技大学大数据科学与工程研究院、国家新闻出版署富媒体数字出版内容组织与知识服务重点实验室(武汉科技大学)、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学)、武汉科技 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}