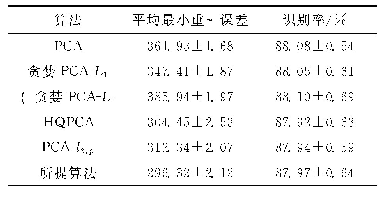
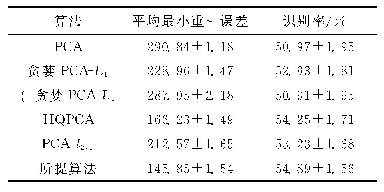
《表3 MNIST数据集上各算法的平均最小重构误差和对应的识别率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
MNIST数据集[21]共包含了70 000幅手写数字图像,其中训练集有60 000幅图像,测试集有10 000幅图像。每幅图像的大小是28×28像素,手写数字位于图像中间。在本实验中,从测试集中选取5 000幅图像,每个字符(即0~9)包含500幅图像。从每个字符的图像中随机选取120幅图像,然后随机选取图像的一部分,将这部分替换为含有椒盐噪声的图像块,图像块的大小取为10×10像素。对于每一个字符,随机选取190幅正常图像和60幅含噪图像作为训练样本,该字符的其他图像为测试样本。实验重复10次。表3是MNIST数据集上各算法的平均最小重构误差和对应的识别率。
| 图表编号 | XD00212299600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 宋昱、孙文赟、陈昌盛 |
| 绘制单位 | 深圳大学电子与信息工程学院、深圳大学深圳市媒体信息内容安全重点实验室、深圳大学广东省智能信号处理重点实验室、深圳大学电子与信息工程学院、深圳大学深圳市媒体信息内容安全重点实验室、深圳大学广东省智能信号处理重点实验室、深圳大学电子与信息工程学院、深圳大学深圳市媒体信息内容安全重点实验室、深圳大学广东省智能信号处理重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}