《表4 实验数据集:Spark下的分布式粗糙集属性约简算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
算法SP-WOFRST与SP-RST都基于经典粗糙集理论(Pawlak粗糙集模型[3]),它们所处理的分类必须是完全正确的或肯定的,因为它是严格按照等价类来分类的,因而它的分类是精确的,亦即“包含”或“不包含”,而没有某种程度上的“包含”或“属于”,因此对噪声的处理能力较弱。UCI上的高维数据集大部分无法满足上述要求,并不适合用于本文的算法测试,而低维数据集虽然符合要求,但由于数据量过少,难以展现实验结果。因此使用了两个人工数据集arsds1与arsds2来测试算法的性能,数据集相关属性见表4。arsds1是一个高冗余度的数据集,其中包含50个互不冗余的必要特征,400个冗余特征以及50个无关特征;arsds2中包含250个互不冗余的必要特征,200个冗余特征以及50个无关特征。即在理想情况下,对两个数据集作特征选择的结果中应当分别包含50个或250个必要特征。
| 图表编号 | XD00133799400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.10 |
| 作者 | 章夏杰、朱敬华、陈杨 |
| 绘制单位 | 黑龙江大学计算机科学技术学院、黑龙江大学计算机科学技术学院、黑龙江省数据库与并行计算重点实验室、黑龙江大学计算机科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |
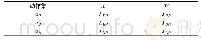




{kind=link}