《表1 PPO算法参数:基于深度强化学习的三维路径规划算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
每个智能体都按照本文所提出的方法不断地学习探索,训练过程中,始终遵循公式(6)进行一定的奖惩。在每一回合规定的最大步长内未到达目的地则-0.5,到达目的地则+1.0。每一回合结束或出现出界的情况则整个场景复位。为了加快训练速度提高训练效果采用多智能体并行训练,虽然10个智能体是独立的个体,但是它们具有相似的观测和动作。本实验总训练次数为1.5×106次,PPO参数设置如表1所示。
| 图表编号 | XD00163035600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 黄东晋、蒋晨凤、韩凯丽 |
| 绘制单位 | 上海大学上海电影学院、上海电影特效工程技术研究中心、上海大学上海电影学院、上海电影特效工程技术研究中心、上海大学上海电影学院、上海电影特效工程技术研究中心 |
| 更多格式 | 高清、无水印(增值服务) |
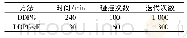





{kind=link}