《表1 训练信息:基于深度强化学习的自动驾驶车控制算法研究》
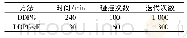 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表1记录了原始DDPG算法和改进的算法的训练过程所消耗的时间和碰撞次数,以及达到收敛的迭代次数。根据仿真时间记录并且结合图5,原始DDPG算法需要240 min的学习才能在Torcs中完整跑完一圈。而本文的算法仅用30 min即可在Torcs中完整跑完一圈。在相同的迭代次数下,原始DDPG算法的学习过程不稳定,而且学习速度较慢,并且收敛到相对稳定的值所需要的时间较长。而改进过的算法则表现较好,根据图5和表1可以看出,DDPGw E算法的学习速度较快,可以很快地收敛到一个较稳定的奖励值。并且,学习的过程非常稳定,所需要的时间也大大缩短。
| 图表编号 | XD00229851000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.10 |
| 作者 | 王丙琛、司怀伟、谭国真 |
| 绘制单位 | 大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院、大连理工大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}