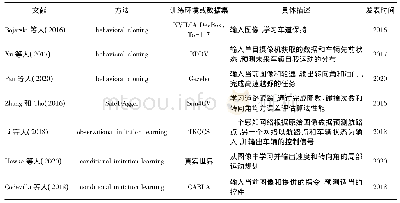
《表2 基于深度强化学习算法的自动驾驶模型训练环境、数据集和方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:WRC为World Rally Championship。
深度强化学习在基于视觉感知的端到端自动驾驶领域得到了较为广泛的应用。最初主要是利用基于值函数的强化学习方法来执行一些离散的驾驶动作(Yu等,2016;Wang和Chan,2017),随着众多基于策略的强化学习方法提出并成功应用于自动驾驶(Kendall等,2019;Jaritz等,2018),驾驶动作空间由离散变为连续,更加符合真实情况。由于强化学习中模型参数指数增长以及人为设定奖励函数较为困难,分层强化学习和逆向强化学习也相继被提出并成功应用于自动驾驶(Shi等,2019;Sharifzadeh等,2016)。表2总结了部分深度强化学习算法在自动驾驶领域的应用。
| 图表编号 | XD00215915800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.16 |
| 作者 | 刘旖菲、胡学敏、陈国文、刘士豪、陈龙 |
| 绘制单位 | 湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、湖北大学计算机与信息工程学院、中山大学数据科学与计算机学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}