《表3 平均Q值和标准差:基于动态融合目标的深度强化学习算法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表2记录了在CartPole-v0问题上三种算法收敛后的平均得分和标准差,定量地分析了图3实验结果,DTDQN算法相比DQN和DSN算法而言,得分上提高了47.2%、16.8%,在稳定性上,标准差减小了55.2%、60.9%。表3记录了在CartPole-v0问题上三种算法收敛后的平均Q值和标准差,定量地分析了图4实验结果,DTDQN算法相比DQN显著减小了Q值的过估计,相对DQN和DSN而言,在收敛后的Q值的稳定性上也得到了提升。
| 图表编号 | XD0035455700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.04.01 |
| 作者 | 徐志雄、曹雷、张永亮、陈希亮、李晨溪 |
| 绘制单位 | 解放军陆军工程大学指挥信息系统学院、解放军陆军工程大学指挥信息系统学院、解放军陆军工程大学指挥信息系统学院、解放军陆军工程大学指挥信息系统学院、解放军陆军工程大学指挥信息系统学院 |
| 更多格式 | 高清、无水印(增值服务) |
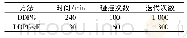





{kind=link}