《表1 超参数:解决深度探索问题的贝叶斯深度强化学习算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先在如图2所示的格子世界中测试BBDQN算法的探索效率,白色部分的格子代表网格世界的规模,灰色格子为终止状态,由于空间限制,图2中的格子世界的规模仅为4×4,而在实验中使用的格子世界的规模为20×20,但这并不妨碍使用图2的小规模格子世界来描述其动态模型。图2中状态S为起始状态,且智能体一直保持一个向右行进的速度+1,在每个状态中可供选择的动作是up和down,即向上和向下,如果选择向上,则下一步会到达当前状态的右上状态,如果选择向下,则下一步会到达当前状态的右下状态。如果智能体处于格子世界的底部,则向下动作可以理解为贴墙行进,此时下一状态将处于当前状态的右方,如果在白色格子的右上角选择动作up就能到达灰色格子的顶部,并获得+1的奖励,其他状态都没有奖励,因此要想获得奖励必须一直选择动作up,然而动作up是有代价的,该代价是和格子世界的规模相关的。假设格子世界的规模为N×N,则每一次选择动作up会带来-0.01/N的奖励,而选择动作down没有代价,奖励为0。其实该问题就是第4章提到的链问题的二维扩展版本,可以将输入表示为一个one-hot矩阵xi∈{0,1}N×N,矩阵中智能体所在的位置为1,其他位置全为0。在该实验中,将同使用ε-贪婪策略的DQN以及Bootstrapped DQN进行比较,BBDQN算法用到的超参数显示在表1中,其中0∈?d代表分量全为0的一个向量。
| 图表编号 | XD00134721000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 杨珉、汪洁 |
| 绘制单位 | 中南大学信息科学与工程学院、中南大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |
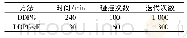





{kind=link}