《表2 参数设置:采用类心密度策略的多目标微分自动聚类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
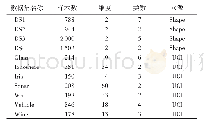
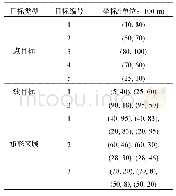
在每个聚类问题中,将前三种算法各自独立运行20次以统计其结果。为了保证算法对比的公平性,规定前三种算法的停止准则都为目标评价次数达到给定的最大值即nmb_obj_max=30 020。本文算法的参数设置依据实验结果调试得到,PSIMACDE和DEAFC_DO算法的参数设置参照文献[10],各算法具体取值如表2所示。前三种算法的交叉概率CR在[CRmin,CRmax]中随机生成。对于第四种RLCLu算法而言,在不改变输入参数的情况下,其每次运行所得的聚类决策图结果均一样,所以操作者可以通过决策图人工选取局部密度相对较高以及与其他密度更高的点之间距离相对较大的点作为类心,来统计其聚类结果。其缺陷是对于一些特殊数据集,通过决策图人工选取聚类中心时容易出错。该算法只需提前定义每个点的邻域个数占总个数的百分比即可,这里定义百分比参数percent=2。
| 图表编号 | XD00107229300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.01 |
| 作者 | 申晓宁、孙毅、薛云勇、孙帅 |
| 绘制单位 | 南京信息工程大学自动化学院江苏省大气环境与装备技术协同创新中心、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大气环境与装备技术协同创新中心、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大气环境与装备技术协同创新中心、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室、南京信息工程大学自动化学院江苏省大气环境与装备技术协同创新中心、南京信息工程大学自动化学院江苏省大数据分析技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}