《表2 样本校正集和预测集统计结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
首先对数据进行样本分集,将38个样品按磷脂含量的多少进行排序,按照一定梯度变化从中选取28组作为训练集样本,用于建立模型,剩下的10组数据作为预测集样本,用于验证模型的适用性,训练集样品和预测样品集的磷脂含量平均值应尽量接近,并且训练集包含样品中的最大值和最小值,样本校正集和预测集统计结果见表2。
| 图表编号 | XD0041248400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 王立琦、刘雨琪、陈颖淑、王雯、王睿智、刘亚楠、张欣、隋玉林、于殿宇 |
| 绘制单位 | 哈尔滨商业大学计算机与信息工程学院、黑龙江省电子商务与信息处理重点实验室、哈尔滨商业大学计算机与信息工程学院、哈尔滨商业大学计算机与信息工程学院、哈尔滨商业大学食品工程学院、哈尔滨商业大学食品工程学院、哈尔滨商业大学计算机与信息工程学院、东北农业大学食品学院、哈尔滨商业大学计算机与信息工程学院、东北农业大学食品学院 |
| 更多格式 | 高清、无水印(增值服务) |



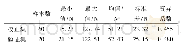


{kind=link}