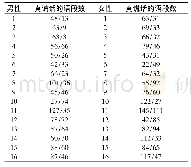
《表2 语音的分割情况:基于SVM和GMM组合分类器的谎言识别方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在数据的分析中我们尝试将语料库中的男性和女性的语料划分开来进行了测试。所以从CSC语料库中选择了16名男性和16名女性的语音数据进行训练和测试。每一个人的录音都包含有真话和谎话。对整段语音的分割情况如表2所示。同时,针对每个人的语段数,我们将90%的语音段用作训练,另外10%的语段作为测试使用。
| 图表编号 | XD0030662100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.02.20 |
| 作者 | 余华、叶超 |
| 绘制单位 | 江苏开放大学、东南大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}