《表2 各分类器数据量:基于多分类器的无分割手写数字字符串识别算法》
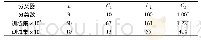 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
系统采用Caffe[12]开源框架实现,实验环境为Ubuntu 64位操作系统,内存32 GB,CPU为Intel Core i5-6300HQ,GPU为Ge Force GTX Titan-X。训练、测试1位数字分类器模型使用NIST SD 19中的数据集,训练、测试2和3位粘连数字分类器使用Synthetic数据集,训练、测试长度分类器的数据集为NIST SD 19和Synthetic均匀分布的混合数据集。数据集样本图片如图7~9所示,由于样本种类较多,从每个分类器的数据集中选取了10类样本作为代表。表2显示了用于三个分类器的训练集和测试集的数据量。所有数据在输入网络之前已将图片尺寸归一化为96×96。
| 图表编号 | XD00163360300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.05 |
| 作者 | 任晓奎、丁鑫、陶志勇、何欣键 |
| 绘制单位 | 辽宁工程技术大学电子与信息工程学院、阜新力兴科技有限责任公司、辽宁工程技术大学电子与信息工程学院、辽宁工程技术大学电子与信息工程学院、阜新力兴科技有限责任公司、中国电网四川阿坝州电力有限责任公司 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}