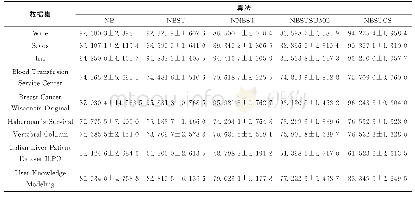
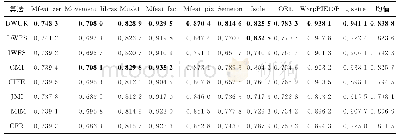
《表3 有标记样本比例为20%时, 5个对比算法在8个数据集上的平均分类正确率 (±标准差) Tab.3 When labeled samples is 20%, the classification
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
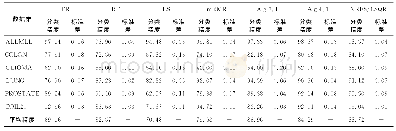
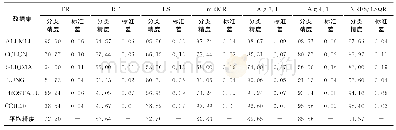
在图4中,随着有标记样本比例的增加,5个算法在9个数据集中的正确率逐渐接近并趋于稳定值。其中NB算法在有标记样本比例高的情况下有运算速度快,准确率高的优势,但在有标记样本不足的情况下,分类精度较低。NBST算法在初始有标记样本分布好的情况下,也有一定优势,整体优于NB算法。NNBST相比NBST算法,在相同条件下得到更高的正确率。NBSTSMUC算法在Blood Transfusion Service Center这个数据集中占有优势。在其他数据集中,样本属性之间的关联不强,朴素贝叶斯分类器效果更好。通过对比,本文提出的NBSTCS算法在各个数据集上有一定优势。
| 图表编号 | XD0029223800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.25 |
| 作者 | 马茂源、吕佳 |
| 绘制单位 | 重庆师范大学数字农业服务工程技术研究中心 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}