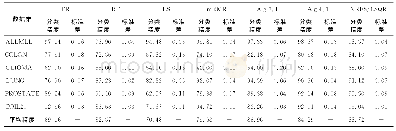
《表3 有标记样本比例为10%时,4个算法在9个数据集上的平均分类正确率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
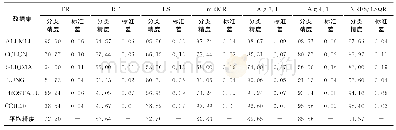
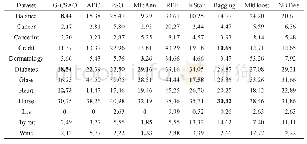
4个算法在9个数据集上各重复10次实验,算法中的参数r=20,近邻参数设置为5。实验中,把每一个数据集随机分为训练集和测试集两部分,其中训练集占80%,测试集占20%。在训练集中随机选取10%的样本作为初始有标记样本,其余样本去除类标记作为无标记样本。4个算法在9个数据集上两个视图的平均分类正确率标准差如表2所示,表3给出两个视图平均分类正确率的实验结果。为了说明有标记样本数目对算法的影响,图2给出了当初始有标记样本比例分别为10%、20%、30%、40%、50%时的平均分类正确率。
| 图表编号 | XD00107096700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.11.15 |
| 作者 | 龚彦鹭、吕佳 |
| 绘制单位 | 重庆师范大学计算机与信息科学学院、重庆师范大学计算机与信息科学学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}