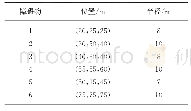
《表1 不同环境下机械臂避障抓捕成功率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实际在训练完成后的测试中,机械臂避障抓取的成功率要高于训练收敛时的成功率,因为在训练时由于探索的需要,算法在每一步选择动作时都有的概率随机选择动作,因此此时的策略并不是学习到的最优策略。实际测试过程中机械臂避障抓捕的成功率见表1。笔者同时对策略梯度法进行实验以作比较,测试结果见表2。在相同测试环境下,由于策略梯度法学习策略的随机性,其测试成功率明显低于深度Q学习方法,从而验证了在机械臂避障抓捕问题上,深度Q学习算法相比其他算法的优越性。
| 图表编号 | XD0025096600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.02.10 |
| 作者 | 王曌、胡立生 |
| 绘制单位 | 上海交通大学电子信息与电气工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}