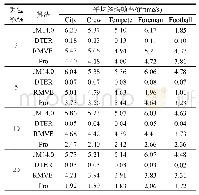
《Table 1 Perplexities of different algorithms》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
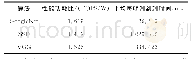
实验结果表明,PPO_GAN算法在多个方面改善了对话生成的质量。本文分析对话生成质量得到改善的原因,首先,Seq2Seq模型存在没有好的评估指标指导模型训练的问题;其次,在使用策略梯度算法训练GAN的时候,存在样本方差大、模型训练困难而且容易收敛到局部最优解的问题。PPO_GAN算法使用GAN的判别模型得到的奖励指导生成模型生成对话,同时通过优化GAN对抗训练的过程,提高了样本的复杂度,并且使对抗训练过程中的生成模型可以单调非减地训练,改善了模型容易收敛到局部最优解的问题。PPO_GAN算法可以更好收敛,从而可以更好地拟合输入对话与生成回复之间的对应关系,改善了对话生成的质量。
| 图表编号 | XD00222663000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 蔡钺、游进国、丁家满 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、云南省计算机技术应用重点实验室、昆明理工大学信息工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}