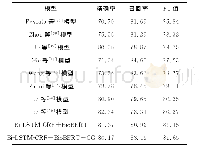
《表4 不同模型的触发词识别性能》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表4列出了已有方法的结果,前3种模型结合大量人工或工具获得的特征,采用SVM模型进行触发词识别。4~8种模型基于词向量采用神经网络模型进行触发词识别。其中Li等[19]基于依存关系的词向量使用并行多池化卷积神经网络进行触发词识别,取得了当前最好的性能,F1值为80.27%,而本文基于深层语境词表示的BiLSTM-CRF即Bi-LSTM-CRF+BioBERT模型,比其高0.88%,加入CG后即Bi-LSTM-CRF+BioBERT+CG模型的F1值比其高1.38%,这说明了本文模型的有效性。与Li等模型相比,本文模型的优越性在于召回率的提高,而精确率略低于Li等模型。根据分析,由于生物医学事件结构复杂,依存分析对句子中事件触发词识别的精确率具有较好的正向作用,Li等模型采用了词语间的句法关系来训练依存上下文信息,从而得到依存词向量。
| 图表编号 | XD00222662300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 魏优、刘茂福、胡慧君 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、智能信息处理与实时工业系统湖北省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}