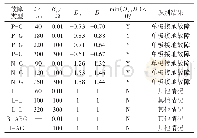
《表7 触发词识别和事件类型识别的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(注:单元格中的“n/a”表示该模型中未列出此任务的结果;表示使用了额外的数据
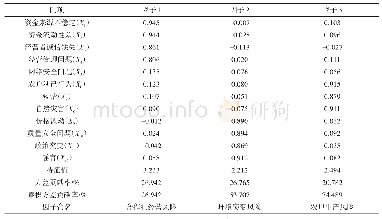
用“正例”扩充训练集主要是为了缓解事件检测任务遇到的语料稀疏与样例分布不平衡问题。上述几个系统的实验结果如表7所示。扩充“正例”后,相对于Joint模型,Joint+FN的触发词识别和事件类型识别任务的F1值分别提高1.8%和1.3%。相对于Bi-LSTM模型,Bi-LSTM+FN的事件类型识别提高0.8%;此外,我们的方法相对于其他未进行语料处理的模型,事件类型识别的F1值均有所提高;而相对于其他扩充语料的模型,也有较大优势,相对于当前通过扩充语料进行事件抽取的模型的最高性能(ANN-FN),我们的方法的F1值提升0.7%,召回率也有很大提高。由此可知:事件类型与框架类型具有强映射关系,使得某些框架类型确实可以表达事件类型,这些框架下的例句在很大程度上能触发对应的事件类型。故将这些例句作为“正例”扩充训练集后,能有效起到丰富训练语料的作用。原本由于训练例句少而无法识别的某些触发词,在语料扩充后,这些触发词具有更多的训练样例,事件检测模型能得到充分训练,故能较好地对其进行识别。为此,该方法对触发词识别与事件类型识别的召回率有明显提升,极大地缓解了ACE语料数据稀疏的问题。正如例2中的触发词“fractured”(骨折),扩充“正例”后,训练语料中包含11条以该词为触发词的例句,训练样本充足,模型可以很好地将该词判定为触发词。
| 图表编号 | XD0054906100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.05.01 |
| 作者 | 张婧丽、周文瑄、洪宇、姚建民、周国栋、朱巧明 |
| 绘制单位 | 苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院、苏州大学计算机科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}