《表1 初始触发词表:触发词与属性值对联合抽取方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
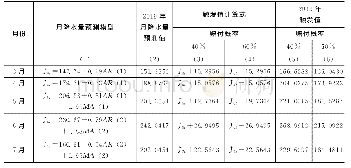
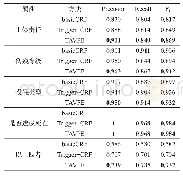
利用1 200篇机动车事故司法判决书的“案情信息”和“证据”部分,分别对两部分内容中用于描述属性的句子进行统计。发现包含描述“投保类型”句子的“案情信息”占总量的89.5%,包含描述“主体责任”的占88.33%,包含描述“伤残等级”的占40.75%,这3个属性是机动车事故司法判决书案情信息部分最常出现的字符串属性;包含描述“是否造成死亡”的占15.75%,是常见的二元语义属性;此外,这4个属性的描述句在“证据”部分也较为常见,可以认为这4个属性是法院对机动车事故类型案件进行判决的重要依据,因此本文以从案情信息中抽取这4个属性为例,验证所提方法的有效性。首先以属性为标签手工标记训练语料中的信息语句;抽取信息语句并依据属性分类;利用基于熵的特征排序方法获得触发词表,如表1所示;借助哈工大的LTP工具[28],对训练语料进行分词、词性标注和依存句法分析,得到特征向量集合;给每个特征向量手工标记一个标签,形成本文的训练集。对于诸如“投保类型”、“主体责任”和“伤残等级”等字符串属性,标签包括:{T,B-A,M-A,E-A,B-V,M-V,E-V,N};对于“是否造成死亡”等二元语义属性,标签包括:{T,N}。
| 图表编号 | XD00163008400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 汪瀛寰、薛婵、包先雨、吴共庆 |
| 绘制单位 | 合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院、深圳市检验检疫科学研究院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}