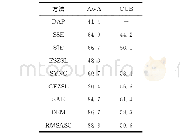
《表2 不同的零样本分类方法在数据集上的正确率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
经过在AwA和CUB的20 000次和30 000次的迭代训练和权重更新,本文得到了在数据集AwA和CUB上的ZSL实验结果,表2给出了本文方法与其它方法的比较结果。本文对比的零样本学习算法有直接属性预测(DAP)[4]、语义相似性嵌入零样本学习算法(SSE)[16]、联合嵌入零样本学习算法(SJE)[6]、一种简单的不可靠约束的零样本学习算法(ESZSL)[8]、合成分类器的零样本学习算法(SYNC)[17]、指数族的零样本学习算法(GFZSL)[18]、语义自编码器的零样本学习算法(SAE)[5]和深度嵌入约束的零样本学习算法(DEM)[10]。
| 图表编号 | XD00206711700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.16 |
| 作者 | 王紫沁、杨维 |
| 绘制单位 | 北京交通大学电子信息工程学院、北京交通大学电子信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}