《表1 混淆矩阵:基于欠采样和代价敏感的不平衡数据分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在数据不平衡的分类任务中,通常使用准确率、召回率、F1-measure值等当作模型的性能度量指标。二分类问题混淆矩阵如表1所示。其中:TP(True Positive)为正例样本分类正确时的情况;FP(False Positive)为反例样本被分类错误的情况;FN(False Negative)为正例样本被分类错误的情况;TN(True Negative)为反例样本分类正确的情况。
| 图表编号 | XD00201762200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 王俊红、闫家荣 |
| 绘制单位 | 山西大学计算机与信息技术学院、计算智能与中文信息处理教育部重点实验室(山西大学)、山西大学计算机与信息技术学院、计算智能与中文信息处理教育部重点实验室(山西大学) |
| 更多格式 | 高清、无水印(增值服务) |




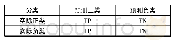

{kind=link}