《表1 混淆矩阵定义:基于随机平衡采样的不平衡数据流分类研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在传统的数据流分类学习算法中,训练精度是主要的评价体系.然而对不平衡数据流问题来讲,以总体分类精度来评价分类器的性能并不适用.例如,在不平衡数据流分类问题中,多类样本占98%,少数类样本占2%,传统的数据流分类算法将所有样本划分为多数类样本,则分类精度可高达98%,但是这样的分类器对少数有用信息的分类精度却很低,训练得到的分类器并无实用价值.不平衡数据流分类算法的目的是不影响多数类学习精度的前提下,提高少数有用信息的分类精度,因此传统机器学习以总体分类准确率为指标的评价体系不适用于不平衡数据流分类性能的评价.针对不平衡数据流的分类评价体系,目前已有很多的研究.例如,基于混淆矩阵的单评价指标,包括F-值、G-均值等,为弥补单评价指标的不足提出的ROC曲线、AUC值,Kappa-error等,其中混淆矩阵的定义如表1所示.为准确评价不平衡数据流的分类性能,本文中采用基于混淆矩阵的F-值、AUC值和ROC曲线作为评价标准.
| 图表编号 | XD0024701400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.01.05 |
| 作者 | 袁磊、季梦遥 |
| 绘制单位 | 武汉大学人民医院信息中心、武汉大学人民医院消化内科 |
| 更多格式 | 高清、无水印(增值服务) |





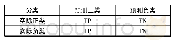
{kind=link}