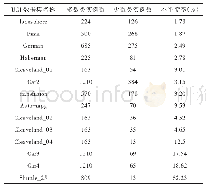
《表4 AUC实验结果:基于混合采样策略的改进随机森林不平衡数据分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于混合采样策略的改进随机森林不平衡数据分类算法》
通过以上实验结果可以发现:过采样生成样本容易导致分类算法过拟合,特别是当数据集可分性较差时,过拟合现象越来越严重。选择较小的过采样因子或者采用较小的过采样因子范围有助于得到较为稳定的分类算法。同时,考虑到不同数据分布的数据集对过采样因子的敏感性不一致,因此本文采用过采样因子为0.2,以及0.2~0.5、0.5~0.8的分类算法与其他分类算法进行比较。表3展示了13个数据集下9种对比算法和本文算法在不同参数下的G-mean值结果。结果表明:当过采样因子参数最佳时(ARIRF_max),本文算法在13个数据集中的9个数据集取得最优结果,在3个数据集上取得第2名的结果。表4展示了AUC的评测结果,结果表明:当过采样因子参数最佳时,本文提出的算法在13个数据集中有10个取得最优结果,在2个数据集上取得第2名的结果。以上结果说明,本文提出的算法相比传统的分类算法可获得更好的分类性能。
| 图表编号 | XD0052840200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.15 |
| 作者 | 郑建华、刘双印、贺超波、符志强 |
| 绘制单位 | 仲恺农业工程学院信息科学与技术学院、广东省高校智慧农业工程技术研究中心、仲恺农业工程学院信息科学与技术学院、广东省高校智慧农业工程技术研究中心、仲恺农业工程学院信息科学与技术学院、广东省高校智慧农业工程技术研究中心、仲恺农业工程学院信息科学与技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}