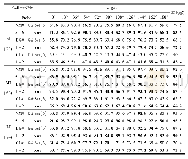
《表1 六种强化学习算法在三种参数组合下的实验评估》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于多层注意力机制—柔性AC算法的机器人路径规划》
由图4~6可知,相比于QL、DQN、DDQN、AC、SAC算法,MPAMN-SAC通过加入柔性函数进行熵增大处理,在多代理系统中引入注意力机制,通过情节数的增长实现更优化的路径规划方案;在第3 000~5 000次情节时段MPAMN-SAC与SAC实现的路径规划开始进入收敛状态,且规划步数显著低于QL、DQN、DDQN算法规划的步数,说明基于行动者—评论家框架的强化学习算法能够有效克服局部最优问题,通过回归学习提高算法的优化性能;另一方面,相比于QL、DQN、AC、SAC算法,MPAMN-SAC的学习稳定性更强,序列振幅更小,充分说明了在强化学习中引入多层并行网络协作机制可以有效提高强化学习的收敛性,通过加强多代理体网络通信功能实现状态值的稳定更新。表1给出了QL、DQN、DDQN、AC、SAC与MPAMN-SAC在三种不同参数组合上的评估指标及其统计量。表1实验数据表明,在不同的参数组合下MPAMN-SAC算法的平均情节学习时间、平均情节步数、步数最小值均小于其他五种强化学习方法,其中具有计算速度快、最优化效果显著的特点,算法性能更强;相比于QL、AC算法,MPAMN-SAC结合深度学习的优势,实现最优化的精确计算;相比于QL、DQN、DDQN三种基于值函数的强化学习算法,MPAMN-SAC算法结合值函数与策略,实现代理体网络动作—状态组合的快速更新。相比于SAC算法,MPAMN-SAC结合深度学习的优势与动态参数,不同参数组合下得到路径规划方案的最小值较SAC平均减少12.47步,每情节的路径规划的平均步数平均减少10.45步,进一步克服行动者—评论家框架的局部最优缺点,实现全局最优化的精确计算。
| 图表编号 | XD00189235300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.05 |
| 作者 | 韩金亮、任海菁、吴淞玮、蒋欣欣、刘凤凯 |
| 绘制单位 | 中国矿业大学数学学院、中国矿业大学环境与测绘学院、中国矿业大学安全工程学院、中国矿业大学信息与控制工程学院、中国矿业大学安全工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}