《表5 部分NMT模型在WMT14数据集上的表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
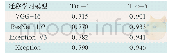
在神经机器翻译、生成式文本摘要、语音识别等生成式任务中,注意力机制一般被用作连接编码器和解码器的桥梁,使解码器在生成每个词项时都可以参考源序列中最相关的部分。多项工作证实了注意力机制在生成式任务中是不可或缺的[3,6]。然而注意力机制不仅可以用于连接编码器和解码器,多头自注意力网络甚至可以替代LSTM或CNN完成编码和解码。表5对比了三种不同网络结构的NMT模型,其中基于多头自注意力网络的Transformer模型用更小的训练开销获得了更好的译文质量,其中在英-德翻译任务中甚至超过了集成(ensemble)模型的表现。该研究认为多头自注意力网络具有两个方面的优势[6]:一是自注意力可以无视距离直接捕捉所有词项间的依赖关系,相比之下,LSTM需要逐步循环才能得到,并且难以捕捉长距离依赖,而CNN则需要通过层叠来扩大感受野(receptive field);二是多头自注意力网络的结构更加简单,计算开销也相对较小,而且和CNN一样不依赖于前一时刻的计算结果,可以并行计算。不过,Domhan[55]的研究表明多头自注意力网络在编码器端的作用比在解码器端的作用重要得多,解码器端即使替换成LSTM或CNN,模型的表现也未见明显下降。
| 图表编号 | XD00174897200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.25 |
| 作者 | 石磊、王毅、成颖、魏瑞斌 |
| 绘制单位 | 安徽财经大学管理科学与工程学院、南京大学信息管理学院、南京大学信息管理学院、山东师范大学文学院、安徽财经大学管理科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}