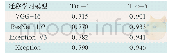
《表4 预训练模型在中文数据集上的性能表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
表3和表4将当下预训练模型相关论文中提到的数据集以及性能得分进行汇总,表3是目前比较常见的SQuAD 1.1和SQuAD 2.0数据集。通过对比可以看出预训练模型优于传统模块分离方式的性能,带来绝对的效果提升。在XLNet以及后续的BERT系列的改进版本中性能逐渐提升,说明预训练模型还需要进一步发展。表4汇总了预训练模型在相关中文数据集上的表现,由表中CMRC、DRCD、DuReader数据集的表现可以看出描述型任务的数据集比抽取型任务的数据集要更复杂、更困难。再通过CMRC与CJRC数据集的性能对比,可以看出专业性较强的任务也会更复杂。CMRC是通用领域的数据集,而CJRC是法律领域的数据集,预训练模型在专业知识较强的领域上还有很大的提升空间。
| 图表编号 | XD00163010700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 张超然、裘杭萍、孙毅、王中伟 |
| 绘制单位 | 陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、陆军工程大学指挥控制工程学院、中国人民解放军73658部队 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}