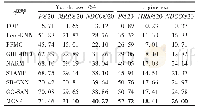
《表3 基于交叉熵损失和基于强化学习训练模型在MSVD数据集上的性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
表3展示了用三种不同的训练方式对本文提出的MIVCf模型进行改进的测试结果。其中MIVCf(Greedy)和MIVCf(Beam)表示使用交叉熵损失函数对提出的基准模型进行训练,Greedy表示使用贪婪搜索解码,Beam表示束搜索解码;MIVCf(CI-DER)表示将MIVCf(Greedy)作为预训练模型,然后利用基于强化学习训练算法来直接优化评价指标CIDER,对模型进一步优化训练得到的结果。从表中实验数据可以看出,MIVCf(CIDER)模型的评价指标得分均高于MIVCf(Greedy)和MIVCf(Beam),证明采用基于自判别序列训练的强化学习算法训练得到句子的质量效果好于贪婪搜索句子的质量。从表中可以看出,虽然模型直接优化的是CIDER指标,但是METEOR和BLEU@4都得到了相应提高。说明直接优化评价指标CIDER的策略梯度算法能够进一步对模型优化,提高视频描述生成句子的质量。
| 图表编号 | XD0078283800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.10 |
| 作者 | 孙亮 |
| 绘制单位 | 中国科学技术大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}