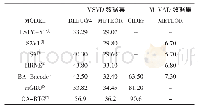
《表2 使用单一语义属性的MIVCf和其他三种模型在数据集MSVD上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为了比较不同语义属性融合策略,通过实验分析本文所提出的基础模型MIVC和其他三种模型的性能比较,这三种模型都采用了高层语义属性,但是语义属性融合的策略不一样,实验结果如表2所示。为了公平地比较各种框架融合策略的差异,表中四种模型均使用单一的语义属性sf和同样的视频特征向量v。其中“LSTM-v/LSTM-vf”模型,v表示视频特征向量,f表示从视频RGB帧学习到的高层语义属性向量sf,vf表示将v和sf串联送到网络中,这些向量值都只在初始时刻输入到标准的LSTM解码器。实际上,LSTM-v是一个标准的编码-解码器模型,网络中没有使用高层语义属性,可以作为一个基准框架。LSTM-vf模型使用v和sf的串接作为LSTM解码器初始时刻的输入。在模型LSTM-vf中,视频特征向量v作为LSTM解码器初始时刻的输入,同时语义属性sf在解码器的每一时刻均输入到网络中,而MIVCf是本文提出的网络模型。从表2可以看出,与其他三种方法相比,MIVCf取得了最好的实验效果,证明了本文所提出的语义融合策略的有效性。尤其是MIVCf的效果远远好于基准模型LSTM-v,这表明了高层语义属性对于研究视频描述问题的重要性。
| 图表编号 | XD0078283900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.07.10 |
| 作者 | 孙亮 |
| 绘制单位 | 中国科学技术大学信息科学技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}