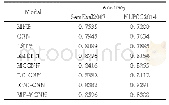
《表6 不同模型在2个数据集上的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
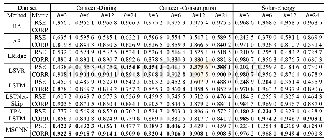
由表6可知,本文提出的MF-MCNN模型在中文和英文数据集都取得了最好的情感分类准确率.很显然,各个模型中英文数据集比中文数据集的分类效果都要好,说明英文文本比中文文本更易于进行情感分类.另外,本文选取的英文数据集不含表情符号,由于表情符号以词语的形式包含在句子中,当短文本中不含情感符号时,模型只是没有提取到表情符号,并不需要修改模型,验证了本文模型的灵活性,便于在实际场景中使用.
| 图表编号 | XD00175962700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.01 |
| 作者 | 陶永才、张鑫倩、石磊、卫琳 |
| 绘制单位 | 郑州大学信息工程学院、郑州大学信息工程学院、郑州大学信息工程学院、郑州大学软件技术学院 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}