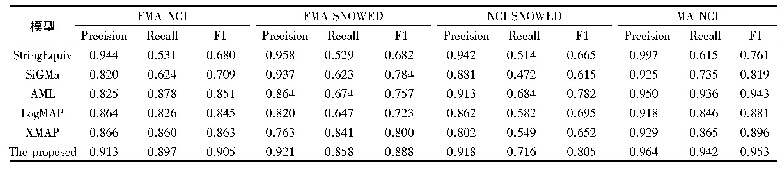
《表1 本体对齐实验各模型在不同数据集上的性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
实验结果如表1所示。在所有的模型中,String Equiv的Precision指标取得了所有模型中最好的效果,但是其Recall和F1值取得了相对最差的效果。造成这个效果的原因是:虽然具有相同字符串的概念大概率可以匹配,但是这种方法无法处理两个匹配概念的字符串差异大的情况,导致了Recall和F1值的降低。AML、Log Map、Si GMa和XMap在Recall和F1值总体上的性能都超过了String Equiv。这些模型都是采用了特征工程的方法,其中AML和XMap都利用递归的方法进行本体对齐,Log Map采用了基于逻辑规则的方法,而Si GMa采用贪婪匹配的方法融合了词典和结构信息。本文所提的模型与基于特征工程的模型相比,各项指标取得了一定的进步。可能的原因是:基于连续向量的方法再加上本文所训练的孪生网络可以更好地计算概念之间的相似度,从而获得更多的匹配概念;本文还考虑了概念的上下文信息。
| 图表编号 | XD00213586900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.10.01 |
| 作者 | 康世泽、吉立新、张建朋 |
| 绘制单位 | 信息工程大学、信息工程大学、信息工程大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}