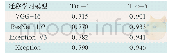
《表1 不同模型在resume NER数据集上的最佳表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
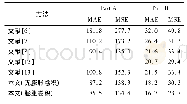
不同模型在数据集resume NER上的最佳表现如表1所示。训练模型主要包括4类,分别是LSTM+bigram、LSTM+unigram、本文模型(双向格子LSTM)+bigram和本文模型(双向格子LSTM)+unigram,其中,bigram和unigram代表两种分词方式,分别是二元分词(将句子每两个字切分一次)和一元分词(将句子每一个字切分一次)。从表1可以看出,应用该模型在该数据集上采用两种分词方式的表现均比使用LSTM的效果好,对于分别使用unigram和bigram分词方式时,与LSTM相比,应用该模型F1分数分别提升了0.27%和2.60%,其余4类指标均得到了有效提升,并且可以看出,此时采用bigram分词方式时效果最好。总之,该模型在resume NER数据集上的效果比LSTM模型好。
| 图表编号 | XD00225220300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 鲍静益、于佳卉、徐宁、姚潇、刘小峰 |
| 绘制单位 | 常州工学院电气信息工程学院、河海大学物联网工程学院、河海大学物联网工程学院、江苏省特种机器人与智能技术重点实验室、河海大学物联网工程学院、江苏省特种机器人与智能技术重点实验室、河海大学物联网工程学院、江苏省特种机器人与智能技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}