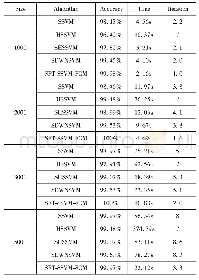
《表7 不同算法在不同数据集上的表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将区间[0,1]×[0,1]分割为10000个点,生成棋盘格数据集,并作为第二个实验的实验数据集.核宽度参数σ∈{0.1,0.3,0.8,1,3,5},惩罚参数C从{0.01,0.5,0.8,1,5,10}中选择.我们从这10000个点中选择样本点组成四个规模递增的训练数据集,剩余样本作为测试集.将SFT-SSVM-FCM模型和SSVM、HSSVM、SHSSVM和SDWNSVM模型作比较.相关的算法性能列于表7.实验分别从分类精度,训练时间和迭代总数来评估算法性能.
| 图表编号 | XD0017160800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2018.11.01 |
| 作者 | 方佳艳、刘峤、吴德、秦志光 |
| 绘制单位 | 电子科技大学信息与软件工程学院、网络与数据安全省级重点实验室(电子科技大学)、电子科技大学信息与软件工程学院、网络与数据安全省级重点实验室(电子科技大学)、西安电子科技大学计算机学院、电子科技大学信息与软件工程学院、网络与数据安全省级重点实验室(电子科技大学) |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}