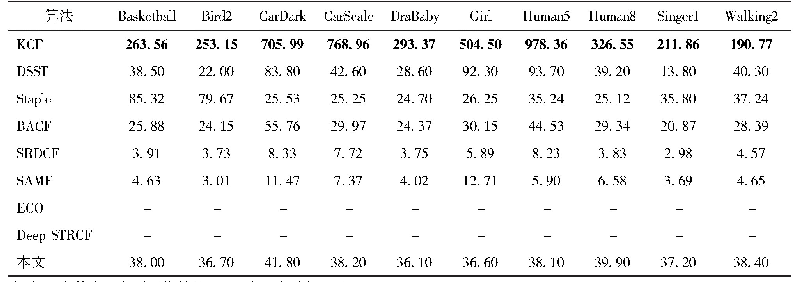
《表5 不同算法在两个完整数据集上的结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
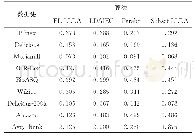
实验结果表明,在训练数据较小的情况下。预训练模型BERT在不完整数据和完整数据上的F1值和分类准确率均高于支持向量机、LSTM和有注意的LSTM模型;对于不完整数据,LSTM加入注意力机制比不加注意力机制的F1值提高4%~10%,而对于完整数据则无明显效果,猜测注意力机制可能对不完整数据更有效,注意力机制能根据上下文语境预测当前最适合的单词;由表4和表5可知,在不完整数据集下的BERT的分类效果比完整数据集下的BERT低6%~7%,因此有必要对系统做进一步改进使其对不完整数据有同样的分类效果。本文提出的模型SDAE-BERT在不完整数据上的F1值和分类正确率均高于BERT及其他模型,与BERT模型相比在F1值和正确率上分别提高约6%和5%(向上取整),从而验证SDAE-BERT能有效地处理噪声问题。表5完整数据集上的分类效果相比表4的不完整数据都有一定提高,表明完整数据更有利于情感分类。表5中SDAE-BERT与BERT模型的实验结果无明显区别,表明提出的模型能够有效地对不完全数据进行情感分类。
| 图表编号 | XD00201773200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.10 |
| 作者 | 罗俊、陈黎飞 |
| 绘制单位 | 福建师范大学数学与信息学院、数字福建环境监测物联网实验室(福建师范大学)、福建师范大学数学与信息学院、数字福建环境监测物联网实验室(福建师范大学) |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}