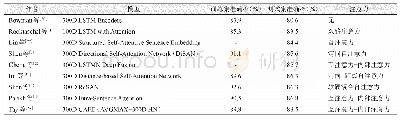
《表4 部分NLI模型在SNLI数据集上的表现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
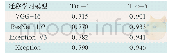
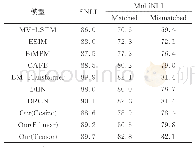
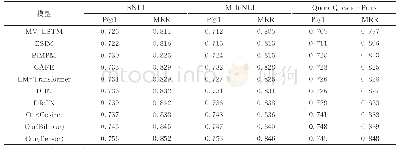
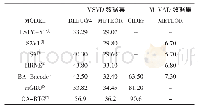
在机器阅读理解以及NLI等推理任务中,既要考虑句子本身的语义,又要考虑句子之间的关系。对于机器阅读理解而言,让两个序列相互关注是较为普遍的做法。表3整理了部分机器阅读理解模型在SQuAD数据集上的表现,可以看出配备双向注意力模型的表现明显优于基线模型;2017年以后该主题的部分工作引入自注意力,进一步提升模型的表现。自注意力可以加强模型对文本自身的理解,在阅读理解中相当于脱离问题去阅读文本,这种做法可以避免带着问题去阅读时可能陷入的局部最优[42]。例如,根据上下文“山姆走进厨房拿起披萨,随后回到客厅准备享用”回答“披萨现在在哪里?”。双向注意力的计算结果可能会发现“披萨”和“厨房”更加相关。然而,自注意力探索的是上下文内部词项间的依赖关系,会将“披萨”和“客厅”联系起来,再结合双向注意力更有可能给出正确的回答。NLI任务中也存在类似的现象。表4整理了部分NLI模型在SNLI数据集上的表现,可以看出互注意力和内部注意力相结合的表现明显优于单独使用互注意力或内部注意力。合理的解释是在NLI任务中弄清句子本身的含义对于判断两个句子是否具有蕴涵关系具有积极意义。
| 图表编号 | XD00174897000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.25 |
| 作者 | 石磊、王毅、成颖、魏瑞斌 |
| 绘制单位 | 安徽财经大学管理科学与工程学院、南京大学信息管理学院、南京大学信息管理学院、山东师范大学文学院、安徽财经大学管理科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}