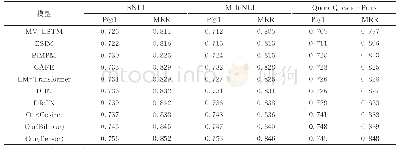
《表2 各方法在SNLI数据集上的实验结果对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
对基于胶囊的英文文本蕴含识别方法在SNLI数据集上的实验结果与其他已公开发表的方法进行了对比,如表2所示.表格中第1部分是由Bowman等提出的基准分类器模型,该方法融合了重叠词、BLEU得分等人工特征[1].第2部分是基于文本编码的模型.第3部分的模型利用了文本之间的交互特征进行蕴含关系识别.由表2可知,基于胶囊的英文文本蕴含识别方法在SNLI数据集上的准确率达到了88.5%,超过所有基于文本编码的方法和基于交互特征的方法.通过集成学习策略整合多个模型的输出结果之后,该方法的性能又得到了进一步提升,准确率达到了89.2%.
| 图表编号 | XD0052007500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 朱皓、谭咏梅 |
| 绘制单位 | 北京邮电大学智能科学与技术中心、北京邮电大学智能科学与技术中心 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}