《表2 乘累加器性能参数:一种面向卷积神经网络加速器的高性能乘累加器》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
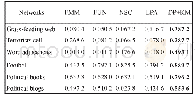
为验证所提出的乘累加器,笔者设计和实现了输入为16位定点数乘8位定点数,输出为32位定点数的乘累加器,最大累加次数为256次。采用verilog硬件描述语言对所提出的乘累加器进行寄存器传输级建模,Modelsim工具用于算法功能验证。采用Cadence Virtuoso工具基于SMIC 130nm工艺库进行原理图和版图的绘制,采用Mentor Calibre进行DRC、LVS验证以及PEX寄生参数的提取,AMS混合仿真工具用于后仿真和验证。所设计和实现的基于传输门的高性能乘累加器版图如图8所示。采用SMIC 130nm工艺,其性能参数如表2所示。乘累加器版图面积为9049.41μm2,tt工艺角下关键路径延迟为1.173ns,800MHz工作频率下的平均功耗为4.153mW。
| 图表编号 | XD00157089200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 孔鑫、陈刚、龚国良、鲁华祥、毛文宇 |
| 绘制单位 | 中国科学院半导体研究所、中国科学院大学、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院大学、中国科学院脑科学与智能技术卓越创新中心、半导体神经网络智能感知与计算技术北京市重点实验室、中国科学院半导体研究所 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}