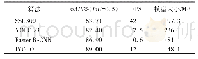
《表4 6种乘累加器整体性能对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表4可知,在最差工艺角下,所提出的基于传输门实现的乘累加器,相比于基于标准单元库实现的相同架构的乘累加器,文献[5-7]提出的乘累加器以及传统乘累加器,速度分别提高了约15.13%、43.72%、15.98%、19.04%和37.42%,面积分别减小了约41.56%、47.01%、45.22%、44.39%和47.87%,功耗分别降低了约48.35%、59.40%、48.74%、54.08%和56.77%。
| 图表编号 | XD00157089500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 孔鑫、陈刚、龚国良、鲁华祥、毛文宇 |
| 绘制单位 | 中国科学院半导体研究所、中国科学院大学、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院大学、中国科学院脑科学与智能技术卓越创新中心、半导体神经网络智能感知与计算技术北京市重点实验室、中国科学院半导体研究所 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}