《表3 卷积映射实例表:一种高性能可重构深度卷积神经网络加速器》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
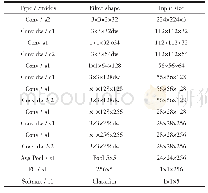
为验证笔者提出的类脑神经元计算阵列及不同卷积映射方法的实现情况,表3分别针对3×3、1×1和7×7卷积映射方式,列举了改进YOLO-v1中几层网络层的配置参数及输入缓存和中间结果的访问情况。其中,每个输入数据占16bit,中间结果占32bit。conv1与fc1采用7×7卷积映射:conv1卷积层每个处理单元内一次性计算8个输出通道,计算阵列上并行3个输入通道和8个输出通道,因此计算阵列一次性足以计算所有通道的卷积,输入特征图全局缓存数据不需要重复访问。由于输入通道为3,将3通道补零为4通道,因此处理单元的实际利用率在7×7卷积处理单元利用率上降低了25%,为65.625%。此外,conv1层之后有池化层,类脑神经元对内部的两个类脑神经元分别计算相邻两行卷积行,因此写入输出缓存中的数据为下采样(即池化层操作)后的结果。conv4卷积层与conv16卷积层均为3×3卷积层,conv7卷积层与conv17卷积层均为1×1卷积,计算阵列在以上4层卷积映射中利用率均达到了100%(有池化层时Pi×Po=256,无池化层时Pi×Po=512)。对输入缓存访问情况分析:实际输入传输量比理论输入传输量减少到了7%以下;fc1层最高,这是因为一方面全连接层不存在行列复用,另一方面输入通道数较多,计算阵列空间并行计算输入通道较多,输出通道较少。对中间结果存储器访问情况分析:表3中的conv1、conv4卷积层及两个1×1卷积层均能够一次性计算完成,不需要存储中间结果;其他卷积的实际中间结果传输量比理论中间结果传输量分别减少到0.59%和3.03%,充分体现了硬件并行结构及映射方法的优势。综合上述分析可知,计算阵列具有较强的并行性,且计算映射方法能够有效减少数据重复访问量。
| 图表编号 | XD0078789500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.20 |
| 作者 | 乔瑞秀、陈刚、龚国良、鲁华祥 |
| 绘制单位 | 中国科学院半导体研究所、中国科学院大学、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院半导体研究所、中国科学院大学、中国科学院脑科学与智能技术卓越创新中心、半导体神经网络智能感知与计算技术北京市重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}