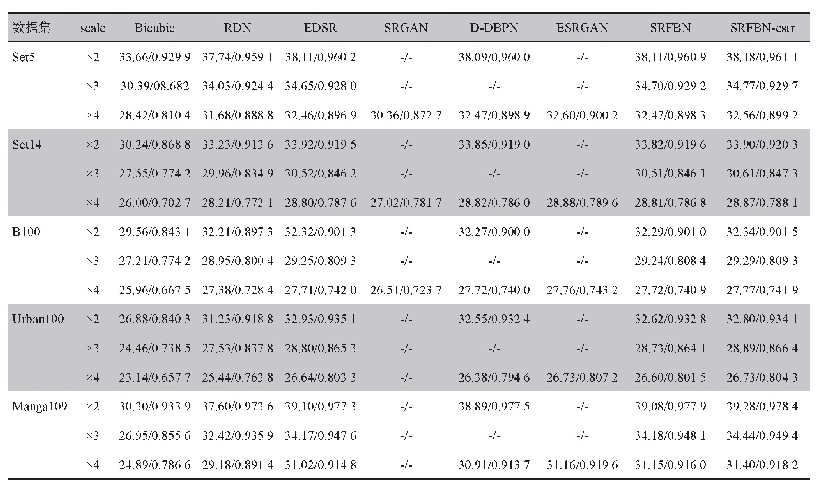
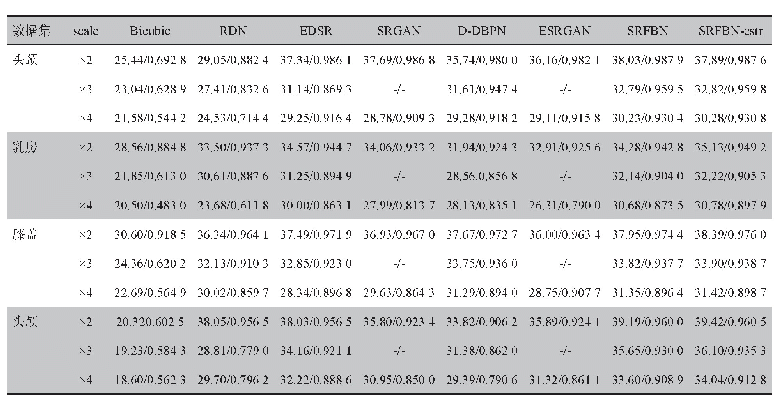
《表1 测试集在不同模型上的训练结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
在本节实验中,设置词向量维度d为200进行计算。通过Word2vec工具包对三种语言语料进行单语词向量训练,分别得到52 947个英语单语词向量、44 805个汉语单语词向量以及39 054个柬语单语词向量。以文献[8]中多语言典型相关分析模型作为baseline,将单语词向量分别放入多语言典型相关分析模型和本章所提出模型中进行训练,得到双语词向量,并将通过多语言典型相关分析模型训练得到的英-汉、英-柬、汉-柬双语词向量所表示的词对与英-汉测试集Ten-ch、英-柬测试集Ten-kh、汉-柬测试集Tch-kh进行分析比较;而后将通过本章模型训练得到的多语词向量所表示的词对与英-汉测试集Ten-ch、英-柬测试集Ten-kh、汉-柬测试集Tch-kh进行分析比较,得到词对之间的相关系数,将本章所提模型的实验结果与基准实验的结果进行对比分析。CCA算法通过Matlab工具实现,斯皮尔曼相关系数越大,所测试的模型得到的双语词向量对应的双语词对相关度越高,实验结果如表1所示。
| 图表编号 | XD00150167800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 蒋亚芳、严馨、李思远、徐广义、周枫 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、云南南天电子信息产业股份有限公司、昆明理工大学信息工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}